How can I learn to code?
How do I learn to code?
People always ask me "how do I learn to code?". I, along with most other developers, always end up saying something like the following:
Learn Python, it's super easy
or
Learn JavaScript. The web makes it easy
or
Learn...
Not that any of that is wrong; but it's not right. One thing we all fail to mention is that they are all tools.
Here is an analogy. My fiancé says I'm terrible at analogies so bear with me with one thing in mind: programming languages are nothing more than tools.
Consider a wall and a picture of your dog on the beach. The wall looks empty and you happen to have a nice frame that would fit that picture perfectly. You get a nail, a stud finder and a screwdriver. (¬_¬)
Yep, you didn't have a hammer and the butt of the screwdriver will do just fine.
This is a lot like programming. I use the tools that I have to get the job done. Most programming languages will do most things. They just do them differently. After a few years in the industry, you will have to start taking into consideration these differences. But to simplify it, here is a Venn diagram:
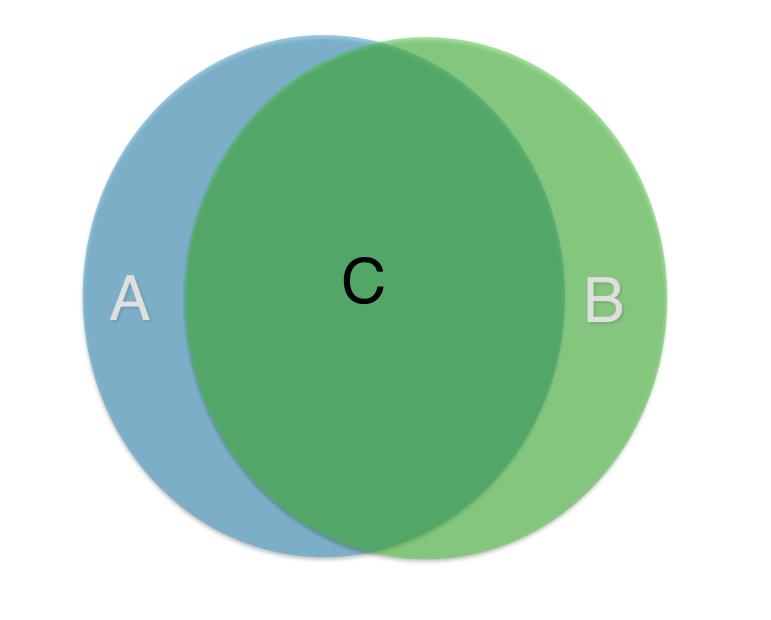
Say A represents one programming language and B represents another. C represents the things that both A and B can do. How well they each do those things is a different story.
Make it do something you need done
The rest of this post isn't as boring. When people ask me "how do I learn to code?", I say don't. Don't learn to code. Just like you never sat down to learn how to hammer or how to screwdriver. Throughout your life you needed things done and you took the tools you had at your disposal and did the job. Now if your job requires you to hammer, you're probably better at it than I am. So my advice is to learn by doing something.
But what do I do?
I don't know what you need; or better yet, I don't know what you need badly enough to work through some bullshit for a lack of a better term. So I thought I'd share a really simple script I wrote recently. But before we get into the code, which isn't much, let's talk about the need.
I recently began reading Einstein's Relativity and the Quantum Revolution: Modern Physics .
Side note: Read this book. It's good. Personally, it's refreshing to re-learn some of this material outside of the competitive/stressful school environment.
Anyways, back to the programming. In the book, the author makes references to Einstein's papers and behaviors. I thought I'd search for those papers, lo and behold, Princeton had them online in their "pdf viewer."
While it's nice of them to put it in that viewer, it's really not mobile-friendly.
So, I decided I wanted a pdf of the content. I did search around for a bit for a pdf version of it with no luck. No, I did not look at torrent websites.
At this point, I had two plans of attack.
A) I hope the viewer isn't flash based, but if it is, I will write a chrome extension that will call their "next page" button and take a snapshot of the screen... then I will have to write another program to crop the pictures and then write some text recognition software and... (seems like a lot of work, doesn't it?)
Let's actually see what we are dealing with...
I opened the book and went to a random page in the book and used the inspect element to view the html. To my relief, the page loads JPEG's into the view as shown in the picture below.
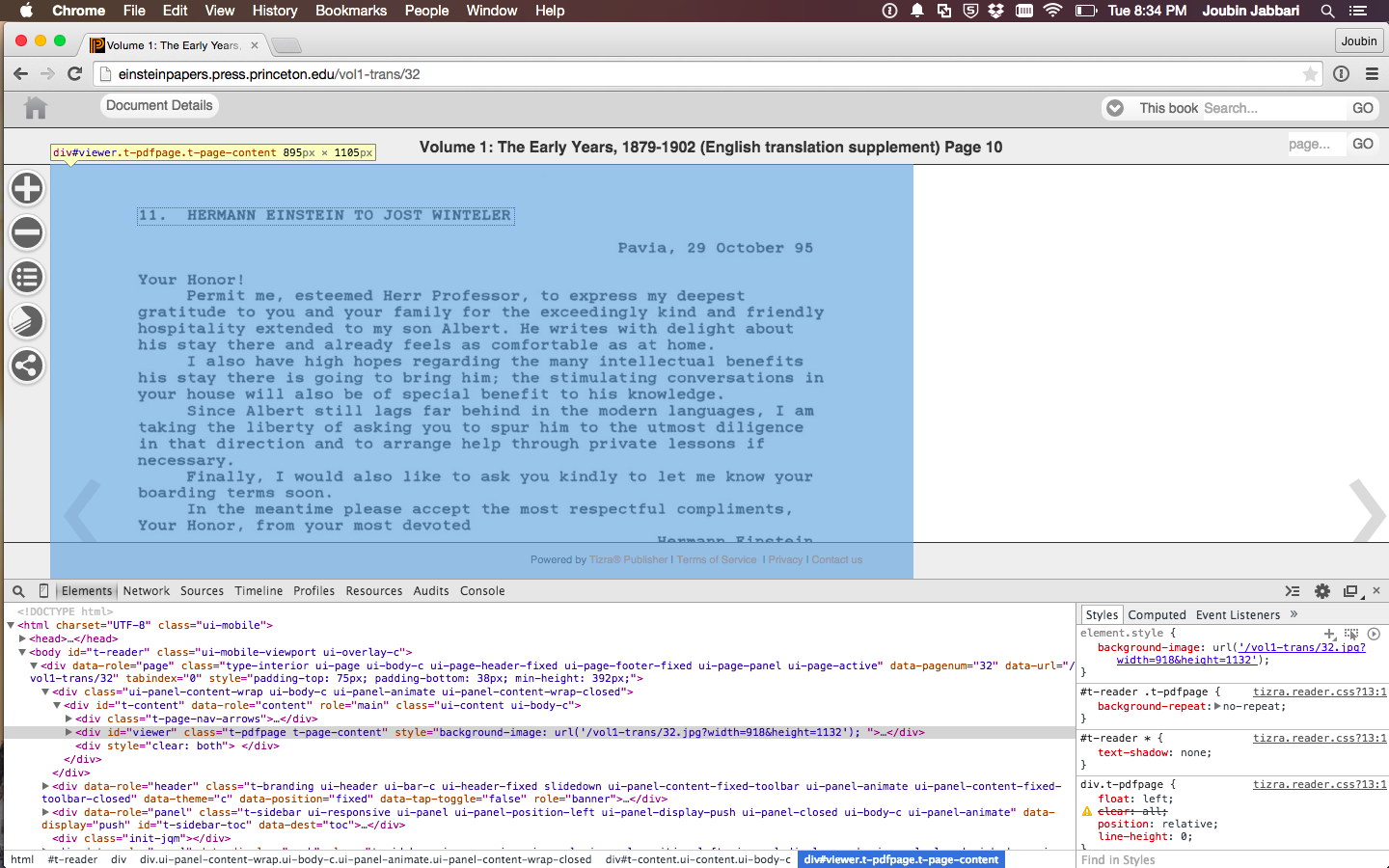
Let's look at the url:
https://einsteinpapers.press.princeton.edu / vol1-trans / page number
After hitting the next page button, I saw that the page number was increasing.
Although I could have written a program in Java, Python, C, C++, C#, Ruby, Groovy, Grails or Objective C, I went ahead and did it with Bash.
The first thing I learned about programming, was to write down everything I needed to do. So, below, I'm going to write down, in plain english, the steps my script needs to take to get me what I want.
Goal: Get every page downloaded as an image to my computer.
So I need to download every page. First I will need the URL of every page. Lucky, their URL scheme is pretty easy. I just need to increment a number.
Code:
for i in {1..5}
do
echo $i
done
Output:
1 2 3 4 5
So a for loop is saying for each item denoted as i in a set of numbers {1 to 5} and do echo (which is like saying print) $i and once you're done with everything between 1 to 5, be done.
Below is some permutations of the same code as above to give you a feeling.
Code:
for i in {1..10}
do
echo The i in this case is: $i
done
Output:
The i in this case is: 1 The i in this case is: 2 The i in this case is: 3 The i in this case is: 4 The i in this case is: 5 The i in this case is: 6 The i in this case is: 7 The i in this case is: 8 The i in this case is: 9 The i in this case is: 10
Get the idea?
So, in the case of our URL, I need to somehow change the URL with each iteration of the for loop to the next page.
Code:
for i in {1..5}
do
echo url/$i.jpg
done
Output:
url/1.jpg url/2.jpg url/3.jpg url/4.jpg url/5.jpg
Pretend that the above URL is really the URL and not the word url. I just kept it as url to keep it readable.
Now I have it outputting the first 5 urls (pictures) of the book. I have two problems here. I need more than just the first 5 pages and simply echoing it does not download it for me.
First let's start by downloading the first 5 pages. A simple googling of "bash download file from url" will result in links that talk about wget and curl. I personally use a Mac and the curl command is installed by default so I went with that. But I'm sure wget will work just as well.
Let's replace echo with curl and some command line options on curl that can be found on it's manual page. Just to summarize, the -O option tells curl to download the page using the servers file name. So, for the first page, it would be 1.jpg.
Code:
for i in {1..10}
do
curl -O https://einsteinpapers.press.princeton.edu/vol$e-trans/$i.jpg
done
The above code will result in the top 10 pictures being downloaded. Next, I saw that I don't want a bunch of files cluttering my desktop, so I made a folder and changed cd my directory to that folder and then I ran my script from there.
The next problem is that I want more than just the first 10 pages. I can change the limit to 100, 200 or any number that I want. Or I can go to the table of contents and see what the last page number is. But... I really wanna download all of the volumes and I really really really don't want to go to each book and find the length of each book. I'm getting bored even thinking about it. So I need a way for the web page to tell me I've gone too far and there are no more pages to download. But first, let's get "too far".
Code:
while [ 1 ]
do
curl -O https://einsteinpapers.press.princeton.edu/vol$e-trans/$i.jpg
done
The problem with the code above is that $i doesn't change. Let's fix that.
Code:
i=0
while [ 1 ]
do
i=$(expr $i + 1)
curl -O https://einsteinpapers.press.princeton.edu/vol1-trans/$i.jpg
done
The while is based on a condition that is in between the brackets. The condition in this case is 1. Most languages consider 1 as true and 0 as false. This comes from on or off. But basically, I'm saying while [ true ] which is to say FOREVER do blah blah blah.
If you don't understand the i=$(expr $i + 1) line don't worry too much. It's just saying take $i and add one to it and save it back to $i. So basic math: i=i+1. If $i is originally 0, the answer will be 1 and $i will be 1 and so on.
Now I will get every page and then some pages that don't exist. Say the book is 200 pages. What happens on page 201? Well, it doesn't exist. After googling around for a bit regarding "missing pages on website", you should come to the conclusion that you're not the only one that needs to know if a page exists or not. Your browser needs to tell you that. So try going to https://www.google.com/somepageThatDoesntExist and you will see the following:
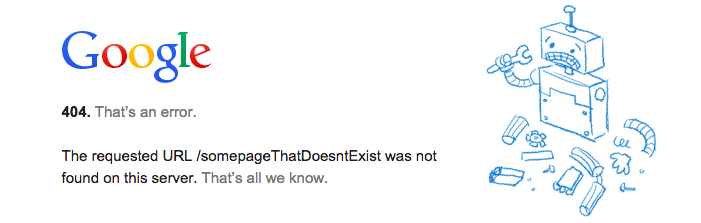
After a few years on the internet, you should be used to seeing those "https status codes". So you google "https status code" and learn that 200 means that the page came through fine. Perfect, so we need to exit if the page does not come through with a 200 status code. Next, I would check to see if I can get the response code from curl.
A few google searches and you can find the answer.
My new approach is going to be to download every page until the site decides to not give you any more data. Let's test that theory before I get started.
I am going to visit https://einsteinpapers.press.princeton.edu/vol1-trans/678912345.jpg. No book should have 678912345 pages. I don't care if it's on the Theory of EVERYTHING.
Yep, as expected. I was redirected away to the main page. If you look at the chrome inspector, you can actually see the 302 code returned by the page right before the redirect.

One of the google searches that resulted in the status code gave me a template of how to get the status code:
curl -O https://einsteinpapers.press.princeton.edu/vol$e-trans/$i.jpg --silent --write-out '%{https_code}\n'
The problem with the above line is that it outputs to the command line, but I really need to save it as a variable.
A little modification and we get:
output=$(curl -O https://einsteinpapers.press.princeton.edu/vol$e-trans/$i.jpg --silent --write-out '%{https_code}\n')
That's pretty much the meat of the code.
Wanna see it?
Code:
mkdir sandbox_1234
cd sandbox_1234
for e in {1..11}
do
mkdir vol$e
cd vol$e
i=0
while [ 1 ]
do
i=$(expr $i + 1)
# sleep 1 # just to be nice
output=$(curl -O https://einsteinpapers.press.princeton.edu/vol$e-trans/$i.jpg --silent --write-out '%{https_code}\n')
if [ "$output" -ne "200" ]
then
cd ..
break
fi
done
done
for i in *
do
cd $i
convert *.jpg output.pdf
cd ..
echo $i started
done
for i in *
do
cd $i
mv output.pdf ../$i.pdf
cd ..
done
mkdir pdfs
mv *.pdf pdfs
rm -rf vol*
In Conclusion
I didn't really write this post to teach a beginner "how to code" but rather "why to code". So please don't read this post and expect to learn how to write bash scripts. This post is really meant to show how you can make computers work for you. I could have gone to EVERY page on that site and downloaded each page by hand. But it was so much easier to spend 10 minutes writing 40 lines of code.
Programming boils down to logic. While condition { do some stuff } means until the condition becomes true, do some stuff. If condition { do some other stuff }: means do the other stuff if the condition is met. That's all programing is. Eventually, you are going to need to learn a lot more about Logical Reasoning, and do some research to understand algorithms and data structures or even apply the basics of Objected Oriented Programming and the beauty of Design Patterns. But everything I just mentioned will only make sense if you've struggled without them.
I know that the first time you try to write your "script" or utility, it will take longer. But over time, you will gain the skills to automate everything and make your life easier.
Please contact me if you need a place to start :)
PS: I don't claim to be a great coder. I just really enjoy it!
July 10 2015